Published on 2019-10-14 18:37 by Pouya Pournasir
The project focuses on exploring Unity Engine’s potential as a benchmark for AI research using the MLToolkit. We developed “GridSoccer,” a 2.5D video game, and employed the policy-based Proximal Policy Optimization (PPO) algorithm to train agents. This was my final year project in 2019.
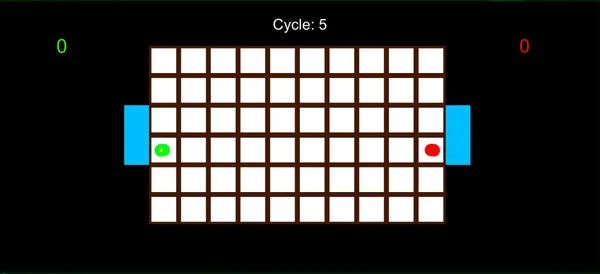
In this game, there are two players: red and green. One player acts as the attacker by having the ball, while the other plays as the defender. The goal is for the attacker to send the ball to the opponent’s goal, while the defender’s objective is to prevent this.
If the attacker and defender end up on the same block, the attacker loses the ball and becomes the defender, while the defender gains the ball and becomes the attacker. Each player can move in four directions, with one block allowed per cycle. For example, in a 0.5-second cycle, players can move one block every 0.5 seconds. Roles reverse in each match.
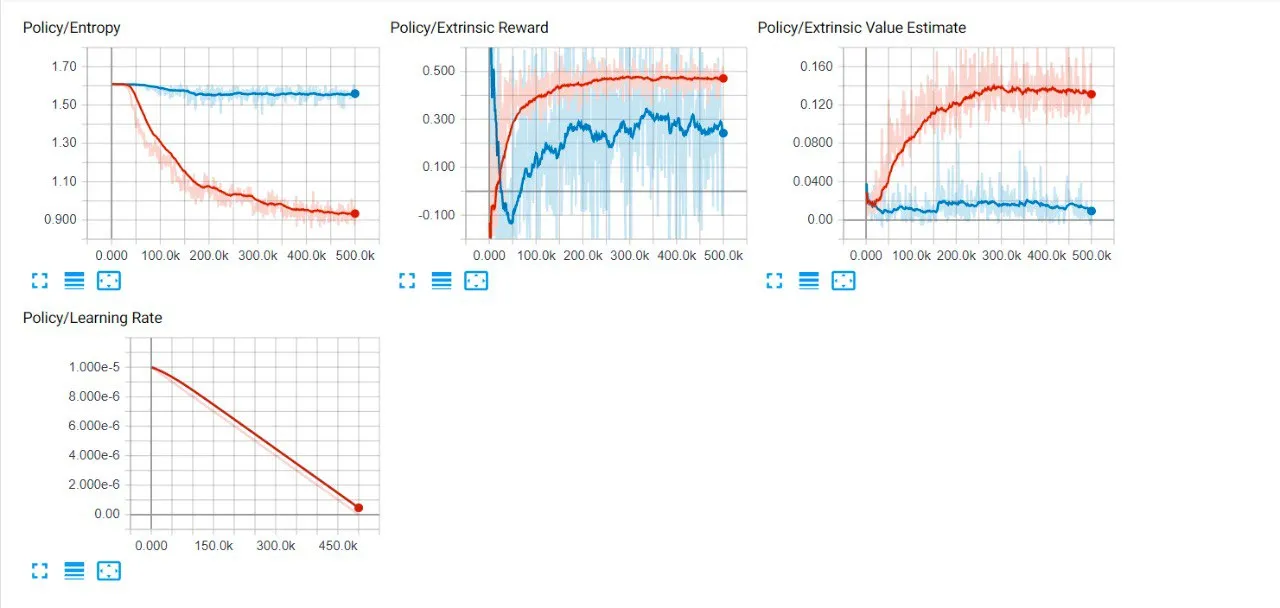
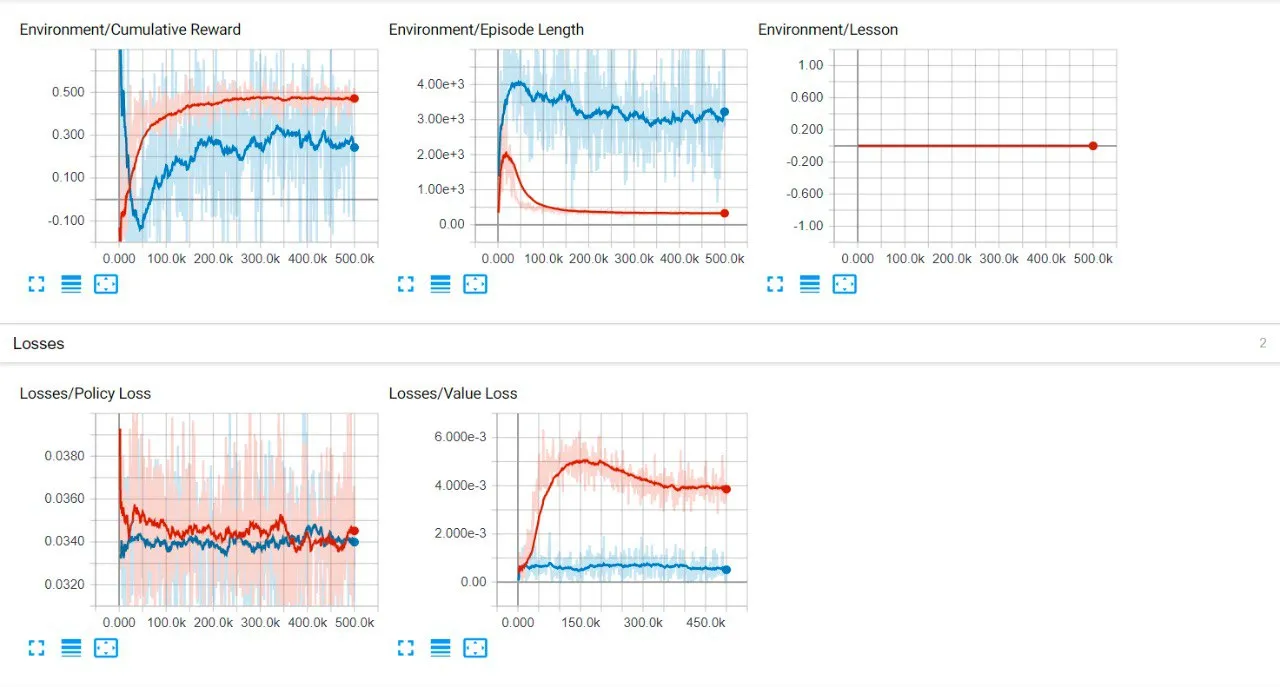
The iteration loop involves agents competing at different stages. Initially, an agent faces an AI with random actions, resulting in inconsistent training (marked in blue). In the subsequent stage (shown in red), there’s a notable 0.2 increase in rewards, indicating a stable and effective learning process based on the beta’s value. This loop continues, with each new agent consistently improving and yielding better outcomes over time.
Our findings indicate that agents excel in learning offensive strategies, swiftly scoring goals. However, defensive learning presents challenges due to a less clear reward function. Defenders must protect their goal, block threats, and retrieve the ball, while attackers primarily aim to reach the goal and evade capture. Although agents haven’t surpassed human performance in both tasks, the iterative process enhances their training in each stage, making them adaptable for similar competitive environments.
Written by Pouya Pournasir
← Back to blog